SVGE v0 工作流
GPT-Image-2 最小可行版本 — 不訓基座模型,純 API,先看見「圖像、mask、JSON」三件套
閱讀結論
SVGE 不是 prompt 生圖工具,而是結構化視覺數據工廠:場景定義語義,mask 定義幾何,JSON 定義真值,QA 決定是否可訓練。
先做 200 張動態事件樣本,不鋪滿全部高速巡檢場景;目標是證明真實測試集效果提升,換取資源與試點。
它負責生成高質候選圖,不負責訓練真值;訓練用 image_aligned_mask 和 final_json 必須在生成後重新建立。
一張普通二值 mask 不夠;最小正確格式是 panoptic scene map + instance masks + overlay masks + final_json。
先看樣例 — 為什麼這件事值得做
讀者應該先看到效果,再看方法。這組 9 張圖展示的是同一類高速巡檢世界:不同天氣、光照、車流、維修設備、警戒區與生成後 mask 都能被組成可驗證樣本。它不是普通高速風景圖,而是把「業務事件」變成「可訓練資料」的第一個證據。


車流、錐形警戒區、箭頭板、照明車。

顏色屬性可控,場景結構穩定。

車燈、尾燈、濕路面反光成立。

彎道、路障、濕路面與遠景一致。

長影、車道、維修設備有物理一致性。

多車輛、警戒區與道路設備同框。

低光色溫、濕路面、錐形警戒區。
這組圖要講的故事:GPT Image 2 先提供高質候選圖,SVGE 再把候選圖轉成 image_aligned_mask、final_json 和 QA 結果。真正值錢的不是單張圖,而是圖像、mask、JSON、風險語義和真實測試提升組成的資料閉環。
SVGE 第 0 階段 — 200 張小型驗證閉環
1. 核心修正:不能再讓方案顯得過度依賴提示詞
目前方向仍然成立:mask 控制幾何,JSON 控制語義,提示詞控制場景。但更準確的公司級定義不是普通 AIGC,也不是「用提示詞生成高速圖片」,而是 結構化視覺數據生成系統。提示詞只是生成條件之一;真值應由 multi-layer mask、structured JSON 和 QA 規則共同定義。
| 控制來源 | 責任 | 第 0 階段最小做法 |
|---|---|---|
| Ontology / scene graph | 定義業務世界裡有什麼,以及物體、病害、事件和區域的關係 | 只做動態事件子集,不做全量高速 ontology |
| Multi-layer mask | 生成後定義幾何真值,不再使用單一二值 mask 表達所有對象 | image_aligned instance / semantic / region mask 三層起步 |
| Structured JSON | 生成後定義語義、風險、交通影響、告警與處置標籤 | 每張樣本都有完整 final_json |
| 提示詞 | 把 mask + JSON 視覺化為合理場景 | 模板化短提示詞,不承擔全部控制責任 |
| QA | 篩掉 mask 不貼合、JSON 不一致、業務位置不合理的樣本 | 生成 260–300 張,保留 200 張 |
2. 終局架構:高價場景數據工廠
完整閉環應該作為第 1/2 階段的公司願景,而不是第 0 階段的即刻交付。第 0 階段的任務是把這套終局架構壓縮成一個可驗證、可展示、可擴張的小閉環。
這條鏈路的核心思想是:用高價場景定義語義,用 scene graph 定義關係,用 multi-layer mask 定義幾何,用 JSON 定義標註,用生成模型補足長尾,用真實測試驗證價值。
3. 第 0 階段不做完整工廠,只做 200 張小型驗證版
如果目標是快速看到效果、拿融資和顯卡,第 0 階段必須聚焦。200 張不能覆蓋全部橋梁、邊坡、路面、事件、應急場景;它應該是一個小樣本實驗,用來驗證「結構化合成數據是否能改善真實測試集上的高價任務」。
第 0 階段的一句話:不是建完數據工廠,而是用 200 張篩選後的結構化合成樣本,證明這個數據工廠值得投資。
| 不在第 0 階段展開 | 第 0 階段採用的最小替代 |
|---|---|
| 全量高速巡檢 ontology | 只做「動態事件巡檢」subset |
| 完整 scene graph 生成器 | 手工規則 + 模板化 scene graph |
| 訓練或微調生成模型 | 使用現成生成後端,先證明合成數據對下游模型有用 |
| 大規模 10k–30k 合成數據 | 生成 260–300,QA 後保留 200 |
| 多場景全面產品演示 | 一個高價場景的真實測試消融實驗 |
4. 為什麼第一版選「動態事件巡檢」
邊坡雨後巡檢更貼近 UAV 高價場景,但 200 張對病害分割偏少,且對圖像質量、mask 精度和真實測試集要求更高。橋梁巡檢價值也高,但裂縫、支座、露筋等目標太細,第一輪生成與標註風險更大。動態事件巡檢最適合快速驗證:目標物清楚,mask / JSON 容易對齊,真實測試圖更容易找到,投資人和業務方也更容易看懂。
| 候選 P0 | 價值 | 第一輪風險 | 決策 |
|---|---|---|---|
| 動態事件巡檢 | 安全通行剛需,演示直觀,適合檢測與分割 | 相對可控 | 第 0 階段首選 |
| 邊坡雨後風險巡檢 | UAV 差異化強,養護痛點明確 | 病害視覺細、真實測試集要求高 | 第 0.5 階段 / 第二輪 |
| 橋梁巡檢 | 高價值、高門檻 | 高清、多角度、細粒度標註要求高 | 第二波重點 |
5. 200 張樣本分配
200 張要極度聚焦,最多 4–6 個核心類別,再加 hard negative 負樣本。不要平均鋪開全部高價場景。
| 類別 | 張數 | 目的 |
|---|---|---|
| 異常停車 | 35 | 高速高頻事件,容易形成基線對比 |
| 拋灑物 / 貨物散落 | 40 | 長尾但高價值,重點看召回率是否提升 |
| 行人闖入 | 30 | 高風險事件,漏報成本高 |
| 動物 / 非機動車闖入 | 25 | 稀缺長尾,合成補樣本最有意義 |
| 應急車道占用 | 30 | 通行保障與路政管理場景 |
| 障礙物 / 路障 / 落物 | 25 | 安全風險與封控場景 |
| hard negative 正常 / 易誤報場景 | 15 | 控制誤報,包含陰影、污漬、反光、樹葉、修補痕跡 |
| 合計 | 200 | 篩選後可用樣本,不是原始生成結果 |
6. 每張樣本必須是結構化資料包
這 200 張不是普通圖片集。每張都要回答業務問題:是否異常、異常在哪、是否影響通行、是否需要告警、是否需要人工復核、下一步處置是什麼。
| 資料層 | 內容 |
|---|---|
| image | 高質高速動態事件場景圖 |
| multi-layer masks | instance mask、semantic region mask、relation / region mask;必要時保留 defect mask 擴展位 |
| objects | id、class、mask_id、mask_type、location、is_abnormal、risk_level、traffic_impact |
| scene_labels | road_type、weather、inspection_task、overall_risk_level、requires_alert、requires_human_review |
| 來源與 QA | 提示詞 / 規格、生成後端、審查人、拒收原因、是否通過訓練可用檢查 |
{
"sample_id": "dynamic_event_000031",
"scenario": "dynamic_event_inspection",
"business_type": "dynamic_event_response",
"scene_context": {
"road_type": "highway",
"weather": "daytime_clear",
"viewpoint": "gantry_or_uav_oblique_view",
"inspection_task": "dynamic_event_detection"
},
"objects": [
{
"id": 1,
"class": "debris",
"mask_id": 12,
"mask_type": "instance_mask",
"location": "right_lane",
"is_abnormal": true,
"risk_level": "medium",
"traffic_impact": "partial_lane_risk",
"requires_alert": true,
"recommended_action": "notify_road_operation_center"
}
],
"scene_labels": {
"overall_risk_level": "medium",
"requires_emergency_response": false,
"requires_maintenance_work_order": true
}
}7. QA 規則:生成 260–300 張,保留 200 張
200 張應該是 QA 後的可用樣本,而不是剛好生成 200 張。小樣本驗證最怕低質樣本污染訓練,所以拒收標準必須前置。
| QA 項 | 拒收條件 |
|---|---|
| 幾何一致性 | object 明顯偏離 mask,病害或物體超出標註區域 |
| 語義一致性 | 圖像內容與 JSON class / risk_level / traffic_impact 不一致 |
| 場景合理性 | 車輛不在道路/車道上,拋灑物漂浮,封控區和事件點空間關係錯誤 |
| 未標註主體 | 額外生成主要車輛、行人、施工機械、病害或事故元素但 JSON 未記錄 |
| 訓練可用性 | 小物體被忽略、畫面過度美化/災難化、生成瑕疵明顯、hard negative 負樣本不夠真實 |
8. 訓練閉環:不先訓生成模型,先證明合成數據對真實任務有用
第一階段不訓「mask + JSON + 提示詞 → 圖像」生成模型。更快、更有商務說服力的驗證,是拿 200 張合成數據做增量微調,看真實測試集是否變好。
| 實驗組 | 訓練資料 | 用途 |
|---|---|---|
| A. 真實數據基線 | 100–1000 張真實訓練圖 | 建立現有能力基線 |
| B. 真實 + 合成 | 真實訓練圖 + 200 張合成圖 | 驗證合成數據是否提升長尾召回率 |
| C. 真實 + 合成 + hard negative | B + 強化 hard negative 負樣本 | 檢查誤報率是否可控 |
| 測試集 | 規則 |
|---|---|
| 驗證集 | 以真實數據為主,可少量合成輔助調參 |
| 測試集 | 只用真實數據,不能用合成圖自測自嗨 |
| 核心指標 | 長尾事件召回率、重大風險漏報率、mAP、誤報率、困難樣本表現 |
9. 對外敘事:小型驗證版不是終局,但足以拿資源
對外不需要說「我們已經建完完整數據工廠」,也不需要暴露底層生成後端。應該說:SVGE 已能把高價巡檢場景轉化為可控、可標註、可驗證的結構化合成樣本,第一個小型驗證版將用 200 張動態事件樣本驗證其對真實模型效果的增益。
最終主線:用高價場景定義語義,用 scene graph 定義關係,用 multi-layer mask 定義幾何,用 JSON 定義標註,用生成模型補足長尾,用真實測試驗證價值。第 0 階段先用 200 張動態事件樣本證明這條路值得投資。
GPT Image 2 機制與標註策略
intent_json、intent_mask、scene graph 只描述「希望生成什麼、出現在什麼位置」。它們可以用來控制生成和做 QA 對照,但不能直接進訓練。
final_json、image_aligned_mask、bbox、class、risk_level 才是訓練標註。它們必須對齊實際生成圖,並通過 QA 後才能進入資料集。
1. 機制邊界:生成前是意圖,生成後才是真值
OpenAI 官方文檔對這件事其實已經給出邊界:GPT Image 2 支援文字生成,也支援圖像編輯;帶 mask 的圖像編輯會用 mask 指導編輯,但這種控制是提示詞驅動,模型不保證完全精確服從 mask 形狀。ChatGPT Images 在 Chrome 裡的選區編輯也一樣,選區不一定精確,編輯可能超出選區。
| 能力 | 適合我們做什麼 | 不能直接拿來做什麼 |
|---|---|---|
| 文字生成圖像 | 快速生成高速巡檢候選圖,補長尾場景 | 不能保證物體精確在指定像素位置 |
| 圖像編輯 + mask | 在正常高速背景中插入拋灑物、小障礙物、行人等目標 | 不能把輸入 mask 當成最終訓練 mask |
| Chrome 選區編輯 | 第 0 階段人工快速試錯,讓小目標更穩定出現 | 不能保證選區邊界就是標註邊界 |
| 高保真圖像輸入 | 保留高速背景、車道、護欄、監控視角等真實感 | 不能替代後驗標註與人工 QA |
因此:輸入 mask 只是 intent_mask;訓練用 mask 必須是生成後重新標註的 image_aligned_mask。
2. JSON 必須拆成兩層:意圖與真值
一張樣本在生成前後應該有兩套 JSON。生成前的 intent_json 表達「我們想要什麼」;生成後的 final_json 表達「圖裡實際有什麼」。模型訓練只能使用 final_json,不能使用 intent_json。
| JSON 類型 | 時間點 | 角色 | 是否進訓練 |
|---|---|---|---|
| intent_json | 生成前 | 定義場景、事件類別、位置、風險、禁止元素和生成約束 | 否,只作為生成意圖與 QA 參考 |
| final_json | 生成後 | 記錄實際 bbox、mask、類別、風險、告警、交通影響與 QA 結果 | 是,作為訓練標註 |
{
"intent_json": {
"sample_id": "dynamic_event_000031",
"scenario": "dynamic_event_inspection",
"target_event": {
"class": "debris",
"location": "right_lane_middle_view",
"size": "small",
"risk_level": "medium",
"traffic_impact": "partial_lane_risk"
},
"generation_constraints": {
"no_unlabeled_major_objects": true,
"no_fire": true,
"no_rescue_scene": true,
"realistic_surveillance_style": true
}
}
}{
"final_json": {
"sample_id": "dynamic_event_000031",
"image": "images/dynamic_event_000031.png",
"objects": [
{
"id": 1,
"class": "debris",
"bbox": [0.62, 0.58, 0.08, 0.05],
"mask_path": "masks/dynamic_event_000031_debris_01.png",
"mask_source": "sam_plus_human_refine",
"is_abnormal": true,
"risk_level": "medium",
"traffic_impact": "partial_lane_risk",
"requires_alert": true
}
],
"qa": {
"matches_intent": true,
"has_unlabeled_major_object": false,
"usable_for_training": true
}
}
}3. Mask 也必須拆成三層
| Mask 類型 | 來源 | 作用 | 是否進訓練 |
|---|---|---|---|
| intent_mask | 生成前由 layout / bbox / 粗區域得到 | 約束「希望事件出現在哪裡」 | 否 |
| image_aligned_mask | 生成後由 SAM、CVAT / Label Studio、人工修正得到 | 對齊實際圖像邊界,作為訓練真值 | 是 |
| qa_delta_mask | 比較 intent_mask 與 image_aligned_mask | 衡量是否偏離原意圖,決定保留或拒收 | 否,作為 QA 證據 |
如果 GPT Image 2 把拋灑物生成得稍微偏左、偏大或邊界自然化,這對視覺真實性可能是好事,但訓練標註不能沿用原始 intent_mask。正確做法是用 image_aligned_mask 訓練,再用 qa_delta_mask 判斷這張圖是否仍然符合業務意圖。
4. Chrome 裡的三種生成方式
| 方式 | 適合類別 | 操作要點 | 風險 |
|---|---|---|---|
| A. 直接生成整張圖 | 異常停車、應急車道占用、行人闖入、動物闖入 | 每次只放一個主事件,指定視角、車道、天氣、風險語義 | 可能多生成未標註主體 |
| B. 正常背景 + 選區編輯 | 拋灑物、小障礙物、落物、小型路障 | 先生成乾淨高速背景,再在車道局部插入目標 | 選區不精確,仍要後驗重標 mask |
| C. hard negative 生成 | 陰影、污漬、反光、樹葉、修補痕跡、車道線破損 | 明確要求「無真實異常」,但畫面容易被模型誤判 | 若太假,無法壓誤報 |
5. 第 0 階段的實際閉環
第 0 階段不應該剛好生成 200 張,而應該生成 400–600 張候選,最後只保留 200 張。這樣才能把 GPT Image 2 的生成波動轉化為篩選優勢,而不是把不穩定樣本硬塞進訓練集。
Mask 數據集設計原則
1. 先區分三種「一張 mask」
| 形式 | 例子 | 是否足夠 | 原因 |
|---|---|---|---|
| 普通二值 mask | 黑底白色裂縫 / 白色車輛 | 只適合窄任務 | 只能表達前景/背景,不能表達多類別、多 instance、風險和場景關係 |
| Semantic label map | 每個像素值代表 road、sky、vehicle 等類別 | 可做語義分割 | 能表達類別,但不能區分同類別的多個實例 |
| Panoptic ID map | 每個像素值代表 segment id,JSON 補 category / bbox / area | 可做高質場景解析 | 同時覆蓋 stuff 區域與 thing 實例,但仍需 metadata 才能訓練 |
所以答案不是「一張圖能不能只有一張 mask」,而是「這張 mask 是普通黑白 mask,還是帶 ID 和 metadata 的 panoptic map」。前者不夠,後者可以作為完整標註系統的一層。
2. 高質數據集的共同規律
| 數據集類型 | 典型做法 | 對 SVGE 的啟示 |
|---|---|---|
| COCO instance | 一張圖有多個 object annotation;每個 instance 有 category、bbox、area、segmentation、iscrowd | 可數物體不能合成一張白色 mask,必須逐 instance 標註 |
| COCO panoptic | 一張 panoptic PNG + segments_info JSON;同時覆蓋 thing 和 stuff | SVGE 應該有一張場景級 panoptic map,用來描述 road、lane、shoulder、vehicle、barrier 等 |
| Cityscapes / Mapillary | 街景數據同時提供 semantic / instance 標籤,並有 ignore / void 規則 | 高速場景要有道路、車道、路肩、護欄、天空、植被等背景結構,不只標異常物 |
| BDD100K | 同時標 object boxes、lane、drivable area、segmentation、tracking、weather、timeofday、scene | 道路巡檢是多任務數據,不是單一分割數據;scene metadata 很重要 |
| Crack500 / DeepCrack | 常用一張二值裂縫 mask,任務是 crack vs background | 如果只做純裂縫分割,binary mask 可用;一旦做巡檢決策,就不夠 |
| RDD2022 / road damage | 多病害類別常用 bbox + class;更細的數據集會加 per-defect mask、severity、asset context | 病害要能區分類型、嚴重度、位置和處置優先級 |
3. 為什麼高速巡檢不能只用一張白色 mask
一張高速巡檢圖通常同時包含三類語義:場景結構、可數物體、業務異常。單一二值 mask 只能回答「哪裡是前景」,不能回答以下問題:
- 這個前景是車、行人、拋灑物、錐桶,還是病害?
- 同一張圖裡有幾個獨立 object?
- 異常在哪條車道、是否在應急車道、是否阻斷救援路線?
- 裂縫或坑洞屬於 road_surface,還是橋面、邊坡、排水溝?
- 陰影、污漬、反光、修補痕跡是否是 hard negative?
- 這個樣本是否需要告警、人工復核、派工或應急處置?
4. SVGE 的四層 mask 設計
| 層 | 文件形式 | 描述內容 | 主要用途 |
|---|---|---|---|
| panoptic_scene_map | 一張 ID PNG + segments_info JSON | road、lane、shoulder、sky、vegetation、guardrail、vehicle、barrier 等非重疊場景結構 | 場景解析、背景合理性、導出 panoptic 格式 |
| instance_masks | 每個 instance 一張 binary mask,或 panoptic map 中的獨立 segment id | car、truck、person、animal、debris、traffic_cone、barrier、equipment | 檢測、instance 分割、事件識別 |
| defect_overlay_masks | 可疊加 binary masks | crack、pothole、seepage、water_damage、rockfall、drainage_blockage | 病害分割、嚴重度評估、養護決策 |
| region_relation_masks | 業務區域 masks | emergency_lane、blocked_lane、rescue_route、risk_area、work_zone、inspection_area | 交通影響、應急路線、Agent 態勢理解 |
關鍵點:panoptic map 負責「互斥場景結構」;overlay masks 負責「疊加業務語義」。不要強行讓一張 panoptic map 承擔所有病害和業務區域。
5. 為什麼 defect 要做 overlay
病害和場景結構常常是重疊語義。一個像素可以同時是 road_surface,也可以是 crack;可以是 shoulder,也可以是 debris risk area。Panoptic map 通常要求一個像素只屬於一個 segment,如果把 crack 直接放進 panoptic map,會把 road_surface 的語義吃掉。
{
"id": 17,
"class": "pothole",
"mask_type": "defect_overlay",
"mask_path": "defect_masks/dynamic_event_000031_pothole_01.png",
"parent_asset": "road_surface",
"lane_position": "right_lane",
"severity": "medium",
"traffic_impact": "partial_lane_risk",
"requires_alert": true,
"recommended_action": "dispatch_maintenance_review"
}這樣才能同時保留「它是道路的一部分」和「它是病害」兩層真值,對養護業務比單層 segmentation 更有用。
6. 第 0 階段的最小標註標準
200 張 dynamic event 不需要一次做到完整道路資產工廠,但最低標準不能低於以下內容:
| 必需項 | 第 0 階段要求 |
|---|---|
| 異常 object | 每個異常 object 都有獨立 instance mask、bbox、class、area |
| 道路區域 | 至少標 road_surface、lane、shoulder、emergency_lane |
| 業務區域 | blocked_lane、risk_area、work_zone、rescue_route 按場景需要標註 |
| JSON 語義 | risk_level、traffic_impact、requires_alert、requires_human_review、recommended_action |
| QA | 是否多出未標註主體、mask 是否對齊、位置是否合理、是否可訓練 |
以下進入第 0 階段技術細節:快速模式如何把樣品包跑起來
摘要 — 快速模式主路徑
- 快速模式(主路徑) — 純提示詞生圖 → SAM 3.1 後驗抽取 (class, bbox, mask) → Qwen3-VL 抽取屬性 → 鬆過濾。對 SVGE 大多數下游任務都夠用。1k 樣本 ~$50–75,半天跑完。
- 嚴格模式(後備) — 第 2 階段鎖三元組 + GPT-Image-2 mask edit + IoU 0.7 驗證。只在做純語義分割訓練資料時才必要。
- 本地 FLUX.2(升級) — 規模化生產時切,邊際成本歸零。
關鍵領悟:樣例顯示 GPT-Image-2 多 instance、屬性綁定、場景元素一致性都很強。之前擔心的「多 instance 串色」問題在實測樣例中不嚴重。對 SVGE 大多數下游任務(檢測、場景理解、機器人感知、VLA 訓練、基準測試),快速模式一條路就夠。
GPT-Image-2 真實樣例分析
前文 9 張圖已經先展示視覺結果;本節只保留判斷證據。這組樣例覆蓋 8 張高速道路生成圖與 1 張後驗 mask,核心價值不是「圖片漂亮」,而是證明同一業務世界可以被生成、被重標、被 QA,最後轉成訓練資料。
能力證據彙整
| 維度 | 樣例證據 | 對 SVGE 的意義 |
|---|---|---|
| 多 instance(4–6 物體) | 每張 4–6 車輛同時存在、各自獨立 | 快速模式下多 instance 可行,不需要 InstanceDiffusion 風格 adapter |
| 屬性綁定 | 白色貨車 / 銀色轎車 / 灰色 SUV / 深色轎車在同圖無串色;圖 2 全白系是提示詞顯式指定 | 屬性提示詞有效,單 instance 描述可控 |
| 場景元素一致 | 6 張都有錐形路障 + 右側警戒區 + 至少 1 個維修設備(箭頭板/維修車/照明車) | 場景模板量產可行,提示詞能穩定召喚行業專屬元素 |
| 時段控制 | 黃昏(1, 5, 6)/ 白天(2)/ 夜雨(3)/ 雨天(4)/ 冷藍晨昏(7, 8)— 光線方向、色溫、強度都對 | 光線軸可控,可直接用提示詞控制黃昏、白天、夜間、雨天、晨昏等至少 5 檔 |
| 天氣控制 | 雨天反射、濕路面、夜雨頭燈眩光、夕陽長影都符合物理 | 天氣軸可控 |
| 視角一致性 | 6 張都是「高架斜俯瞰、3–4 車道、視野往遠方收斂」 | 相機視角可控,能保持構圖風格 |
| 物理細節 | 陰影方向、紅色尾燈滲色、路面斑剝、輪胎水霧都真實 | 細節品質高,下游模型不容易學到生成瑕疵 |
| 行業場景元素 | 道路維修場景的箭頭板、警示斜紋、維修車形態、照明車都對 | 基底訓練分布覆蓋此場景,無需額外 LoRA |
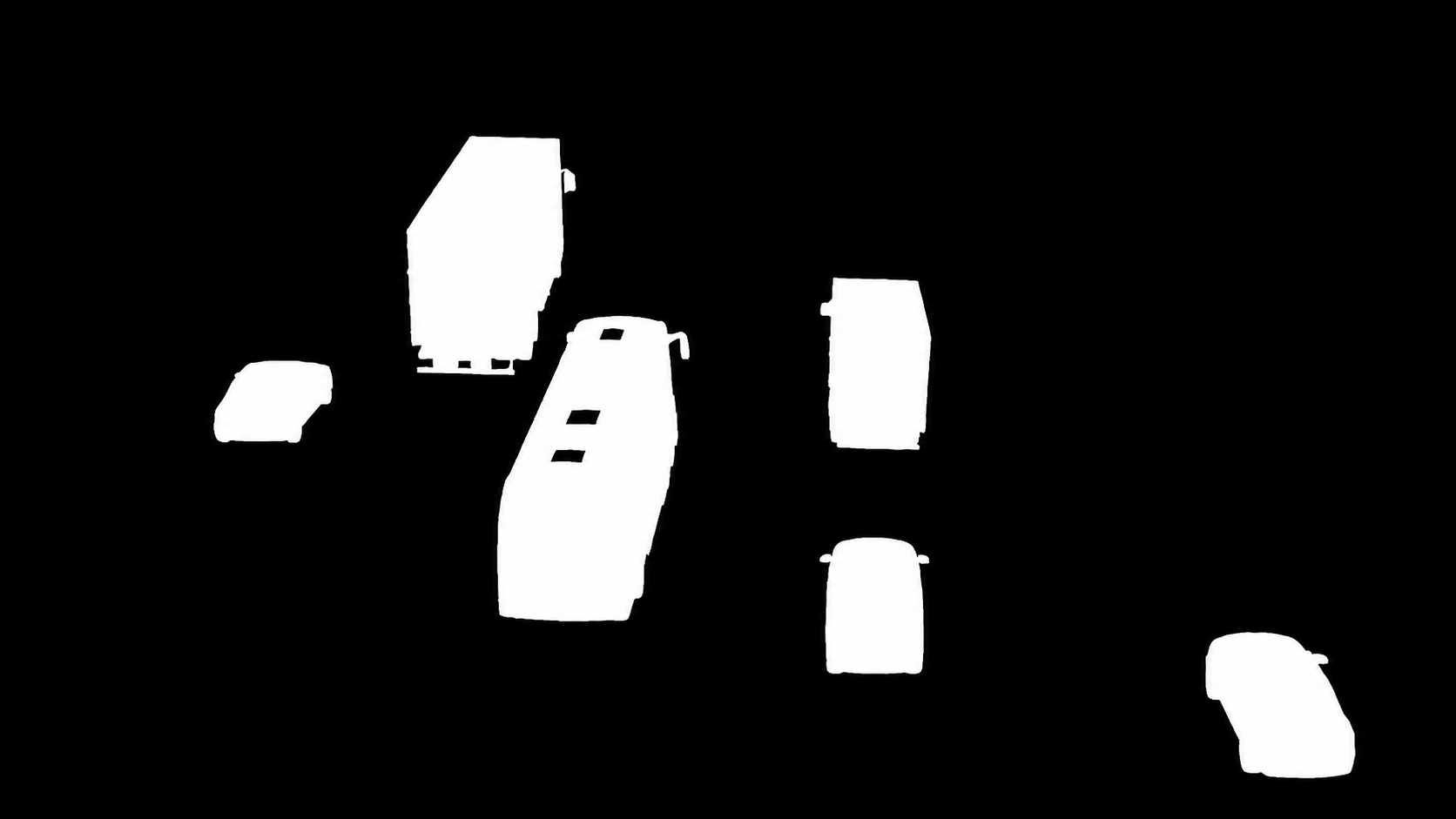
Mask 標註參考樣例(第 4 階段後驗輸出格式)
前文展示的 mask 範例對 7 個車輛 instance 做了二值前景分離。每個白色區塊代表一個 instance,背景與物體分離,邊緣連續、無明顯破碎雜訊。這正是 SVGE 管線第 4 階段(SAM 3.1 後驗 + 人工修正)的目標輸出格式,可轉成 COCO RLE、PNG 索引或多通道 instance mask。
| Mask 屬性 | 本範例 | SVGE 規格目標 | 狀態 |
|---|---|---|---|
| 解析度 | 1672×941(與 GPT-Image-2 輸出 1:1 對齊) | 1:1 與生成圖一致 | ✅ 對齊 |
| Instance 分離 | 7 個獨立白色區塊 | 每個 instance 獨立通道 | ⚠️ 此圖是合成單通道;實際管線需拆成 N 通道 |
| 邊緣品質 | 連續、無洞、無雜點 | SAM 3.1 級別 | ✅ 達標 |
| 覆蓋完整性 | 含車身輪胎 + 後輪罩 | 不丟細節 | ✅ 達標 |
| 背景純淨度 | 純黑、無偽前景 | 無假陽性 | ✅ 達標 |
下游任務對 mask 精度需求
SVGE 主文件 §1.3 列了 6 類下游服務。並非所有下游都需要嚴格 mask 邊界精度:
| 下游任務 | 對 mask 邊界精度需求 | 快速模式是否足夠 |
|---|---|---|
| 檢測(YOLO 等) | bbox 為主,mask 粗細可接受 | ✅ 完全夠 |
| Instance 分割(Mask R-CNN) | mask IoU > 0.5 | ✅ SAM 3.1 後驗能達標 |
| 細粒度語義分割 | 邊界需要像素級精確 | ⚠️ 邊界場景,視任務而定 |
| 場景理解 / VLM 訓練 | 不需要精確 mask | ✅ 完全夠 |
| 機器人感知 / VLA 訓練 | bbox + 粗 mask 即可 | ✅ 完全夠 |
| 基準測試 / 演示 / 邊角案例擴展 | 視覺合理即可 | ✅ 完全夠 |
結論:SVGE 主文件列的 6 類下游,5 類用快速模式就夠。嚴格模式只在做純語義分割訓練資料時才必要。這是「快速模式為主路徑、嚴格模式退到後備」的合理性所在。
判斷演進 — 三輪收斂
| 輪次 | 我答了什麼 | 狀態 |
|---|---|---|
| 第 1 輪 | 圖像優先:GPT-Image-2 純提示詞生圖 → SAM 3.1 反推 (class, bbox, mask) | 部分對(快速模式路徑),但沒明說違反 SVGE mask-first 主路徑 |
| 第 2 輪(用戶駁) | 用戶問「(class, bbox, mask) 不是應該一起定好嗎」 | — |
| 我改答 | 嚴格 mask-first:用戶提供 mask → GPT 編輯 → 系統不抽,只驗證 | 部分對(嚴格模式路徑),但對「先要點結果」太重 |
| 用戶再駁 | 「不對,再看 HTML」 | — |
| 第 3 輪(這次) | 承認兩種模式都有效,按目標選;輸出 mask 本來就該對齊生成圖,而不是直接沿用用戶規格 mask | 應該對齊正確了 |
進一步判斷 — 三個更深問題
問題 1:輸出 mask 悖論
- 第 2 階段 mask = 用戶意圖位置(矩形 / 區塊從 bbox 派生,或 SAM 從參考圖切出)
- 但生成圖的實際邊界不會 100% 服從第 2 階段 mask
- 若輸出 = 第 2 階段 mask,mask 不對齊圖像 → 下游訓練有噪聲
- 若輸出 = 後驗 SAM refined mask,對齊圖像但偏離意圖
真正答案:輸出 mask = 第 4 階段與圖像對齊的 refined mask。但用 IoU(refined, stage2_intent) > 0.7 作為「服從度」門檻,IoU 太低就拒收整個樣本。(class, bbox) 從用戶意圖保留,mask 對齊實際生成圖。
問題 2:「三角一致」的真正定義
(圖像、對齊圖像的 mask、描述圖像的 JSON)
- 圖像 是事實基準(source of truth):實際生成出來什麼就是什麼
- mask 對齊圖像,否則訓練有噪聲
- JSON 描述圖像,否則標籤錯
- 用戶規格 = 意圖(intent),是拒收的依據,不是輸出的內容
問題 3:圖像編輯模式的多 instance 限制
images.edit 的帶 mask 編輯模式,不是說 GPT Image 2 的整圖生成不能處理多 instance。整圖生成在道路維修樣例裡表現很好;真正不穩的是「多個 mask + 多個互斥屬性」想在一次編輯裡精準綁定。
- 合併全部 mask + 全局提示詞 → 屬性串色(紅色轎車 + 白色貨車 → 顏色亂)
- 逐 instance 編輯 → 多次 API 調用,後面覆蓋前面,又貴又不穩
- 若需要 3 個以上 instance 同時滿足精確 mask 邊界與互斥屬性,應改用快速整圖生成 + 後驗標註,或切 FLUX.2 + ControlNet
快速模式 — 主路徑(細節)
適用場景(基於樣例校準後擴大)
- 主要:規模化生產檢測、instance 分割、場景理解、機器人感知、VLA 訓練、基準測試的訓練與驗證資料
- 演示 / 樣本探索 / 驗證框架能跑通
- 規格包含 1–6 個 instance(樣例證明能撐多 instance + 屬性不串色)
- 對 mask 邊界精度要求 IoU > 0.4–0.5 即可(見 IoU 校準表)
- 用戶給 (class, bbox, attrs),mask 不給也行(後驗 SAM 抽)
快速模式管線
- (class, bbox, mask) 三元組在 第 4 階段一次決定,由 SAM 3.1 從生成圖抽出
- 用戶規格的 bbox 只用來驗證 SAM 結果是否大致對齊(鬆 IoU 0.5),不強制
- 輸出 mask 自然對齊圖像,沒有 mask 與圖像不對齊的問題
- 拒收率預期 20–35%(樣例校準後從 30–50% 下調,因為 GPT-Image-2 命中率比預期高)
提示詞構造範本(bbox → lane)
樣例顯示 GPT-Image-2 不擅長精確 bbox 控制,但很擅長「語義位置」(左/中/右車道、近/中/遠視野)。所以 v0 的提示詞構造把 bbox 翻成自然語言位置:
def build_prompt_from_spec(spec):
parts = []
# 1) 場景骨架(樣例都吃這套)
parts.append(f"{spec.scene.style} aerial view of a highway")
parts.append(spec.scene.lighting) # "sunset" / "daytime" / "night with rain"
if getattr(spec.scene, 'weather', None):
parts.append(f"in {spec.scene.weather} weather")
# 2) per-instance 描述(GPT-Image-2 能處理的精度)
for obj in spec.objects:
color = obj.attributes.get('color', '')
location = bbox_to_lane(obj.bbox) # ★ 關鍵轉換
parts.append(
f"a {color} {obj.class_name} in the {location}"
)
# 3) 場景一致性元素(樣例都有:cones / arrow board / maintenance vehicle)
if spec.scene.background == "road_inspection":
parts.append("orange traffic cones lining the right shoulder")
parts.append("yellow arrow signal board on the right")
if spec.scene.background == "highway_construction":
parts.append("road maintenance vehicles with red and white chevron warning patterns")
return ", ".join(parts)
def bbox_to_lane(bbox):
"""把 normalized bbox 轉成「車道 + 視野位置」的自然語言。
Args:
bbox: (x, y, w, h) all in [0, 1]
Returns:
str like "left lane in middle view" / "right shoulder in foreground"
"""
x, y, w, h = bbox
cx = x + w / 2
cy = y + h / 2
# 水平位置 → 車道
if cx < 0.25: lane = "left lane"
elif cx < 0.45: lane = "left-middle lane"
elif cx < 0.55: lane = "middle lane"
elif cx < 0.75: lane = "right-middle lane"
elif cx < 0.92: lane = "right lane"
else: lane = "right shoulder"
# 垂直位置 → 視野遠近
if cy < 0.30: depth = "far view"
elif cy < 0.55: depth = "middle view"
elif cy < 0.80: depth = "near view"
else: depth = "foreground"
return f"{lane} in {depth}"
快速模式 IoU 門檻校準表
不同下游任務對 mask 精度的容忍度不同。快速模式的 SAM-bbox-IoU 過濾門檻應依下游任務動態調整,避免「一刀切 0.5」帶來的浪費或品質不足:
| 下游任務 | 建議 IoU 門檻 | 預期通過率 | 備註 |
|---|---|---|---|
| 檢測(YOLO 等 bbox-only) | 0.3(鬆) | ~85% | bbox 才是標註真值,mask 只是輔助 |
| Instance 分割(COCO-style) | 0.5(標準) | ~70% | 標準 COCO mAP 門檻 |
| 場景理解 / VLM 訓練 | 0.4 | ~80% | 不直接用 mask 訓練 |
| 機器人感知 / VLA 訓練 | 0.4 | ~80% | 抓取需大致位置即可 |
| 細粒度語義分割 | 0.7(嚴) | ~30% | 應切嚴格模式或 FLUX.2 + ControlNet |
| 演示 / 基準測試多樣性 | 0.3(鬆) | ~85% | 視覺合理即可 |
filter.mask_bbox_iou_threshold 欄位,按下游任務動態設置。預設 0.4(兼顧通過率與品質),生產分割訓練資料時切 0.5 或 0.7。
嚴格模式 — 後備(細節)
什麼時候才需要切過來
- 純語義分割訓練資料(ADE20K / Cityscapes 風格的精確邊界 mask)
- 用戶規格要求物體精確在指定 bbox(誤差 < 30%)
- mask 邊界 IoU 必須 > 0.7
- 用戶有給 mask 或參考圖,且下游真的需要嚴格邊界
多數時候你不需要切過來。快速模式的 SAM 3.1 後驗抽 mask 對 6 個下游任務的 5 個都夠用。
嚴格模式管線
- (class, bbox, mask) 在 第 2 階段鎖定意圖(locked_triples)
- 第 3 階段用 mask 作為條件式約束生成(GPT-Image-2 mask edit)
- 第 4 階段角色是 驗證 + 細化,不是「重新抽一個」
- 輸出 mask = 與圖像對齊的 verify_mask,但通過 IoU 0.7 確認對得住意圖
- 拒收率預期 70-80%(嚴格 IoU 門檻會多拒收)
兩模式對照
| 維度 | 快速模式 | 嚴格模式 |
|---|---|---|
| (class, bbox, mask) 在哪定? | 第 4 階段後驗(SAM 抽取) | 第 2 階段派生鎖定 |
| 用戶規格的 mask 角色 | 選用,沒給也不影響 | 核心輸入(沒給就派生) |
| 用戶規格的 bbox 角色 | 驗證 SAM 結果(鬆 IoU 0.5) | 強制條件 + 驗證 IoU 0.7 |
| GPT-Image-2 用法 | images.generate 純文字 | images.edit 帶 mask |
| 多 instance 處理 | 較好(單次生成,無 mask 串色) | 較差(mask edit 屬性串色,需逐 instance) |
| 適合規格複雜度 | 1–4 個 instance | 1–2 個 instance(單次)/ 1–3 個 instance(逐個處理) |
| 輸出 mask | SAM 抽取(自然對齊圖像) | SAM verify_mask(對齊圖像,且 IoU > 0.7 確認對得住意圖) |
| 拒收率(預期) | 30-50% | 70-80% |
| 每 1k 通過樣本的 GPT-Image-2 成本 | 1.5k 張 × $0.05 = ~$75 | 4k 張 × $0.05 = ~$200 |
| 適合目標 | 先看結果、演示、樣本探索 | 下游檢測 / 分割訓練資料 |
| 對應 SVGE 主文件 | 更接近 B 子系統範式 | 對齊 A 子系統 §8.A |
GPT-Image-2 的硬限制
① Mask edit API 不是 ControlNet 級別的條件約束
| API | 輸入 | 實際行為 |
|---|---|---|
images.generate | 提示詞文字 | 無位置控制 |
images.edit | 圖像 + mask + 提示詞 | mask alpha=0 區域「鼓勵」編輯,但邊界會軟化,不像 ControlNet 強制 |
| FLUX.2 / SD 3.5 + ControlNet | 圖像 + ControlNet 條件 + 提示詞 | 嚴格 mask 條件,邊界精度高 |
② 多 instance 的三條替代路徑
| 方案 | 適合 | 缺點 |
|---|---|---|
| A. 全部合成 + 全局提示詞 | 屬性不衝突 | 屬性互衝會串色 |
| B. 逐 instance 編輯 | 強制屬性精確 | N 次 API 調用、後面改前面、貴又不穩 |
| C. 切 Gemini 2.5 Flash Image | 多參考圖原生支援 | 不是 GPT-Image-2,但用戶可能要重新評估 |
| D. 切本地 FLUX.2 + ControlNet | 最嚴格 + InstanceDiffusion 風格單 instance 控制 | 需 GPU、需自己部署 |
③ 切換到本地基座模型的觸發點
- 嚴格模式 IoU 中位數 < 0.7
- 拒收率 > 80%
- 單 instance 屬性串色 > 30%
- 單張平均成本 > $0.5(包含拒收重跑)
成本估算
快速模式 — 1k 樣本(樣例校準後)
| 項目 | 量 | 單價 | 小計 |
|---|---|---|---|
| GPT-Image-2 生成(拒收 25%,樣例校準) | 1.3k 張 | ~$0.04-0.05/張 | $52-65 |
| SAM 3.1 推理(本地 RTX 4090) | 1.3k 張 | 免費 | $0 |
| Qwen3-VL 8B 本地 | ~3-5k instance | 免費 | $0 |
| SigLIP 2 評分 | 1.3k 張 | 免費 | $0 |
| 合計 | — | — | $52-65 |
樣例顯示 GPT-Image-2 在道路維修場景命中率高,拒收預期從原估的 33% 下調到 25%。實際數字以 D2(100 張壓力測)為準。
嚴格模式 — 1k 樣本
| 項目 | 量 | 單價 | 小計 |
|---|---|---|---|
| GPT-Image-2 編輯(拒收 75%) | 4k 張 | ~$0.05/張 | $200 |
| 多 instance 逐個編輯加成(平均 1.5×) | +50% | — | +$100 |
| SAM 3.1 + Qwen3-VL(本地) | — | 免費 | $0 |
| 合計 | — | — | $200-300 |
切到本地 FLUX.2 — 1k 樣本
| 項目 | 量 | 單價 | 小計 |
|---|---|---|---|
| FLUX.2 [klein] 9B 本地推理 | 3k 張(拒收 67%) | RTX 4090 ~6 秒/張 | 5 小時電費 ≈ $0 |
| 初始模型下載 | ~18 GB | — | — |
| SAM 3.1 / Qwen3-VL / SigLIP 2 | — | 免費 | $0 |
| 合計 | — | — | ~$0(電費忽略) |
結論:快速模式是「先看點結果」最便宜的路($75 / 1k 樣本,半天)。嚴格模式是中介選項。真要規模化生產訓練資料,本地 FLUX.2 邊際成本歸零是長期解。
v0 → v1 升級觸發點
程式骨架
對應 prototype_v0/src/,新增 v0_workflow.py 統一兩模式 entry point:
from openai import OpenAI
from sam3 import SAM3Predictor
from transformers import AutoModel, AutoProcessor
import numpy as np
class V0Workflow:
def __init__(self, mode: str = "quick", config: dict = None):
assert mode in ["quick", "strict"]
self.mode = mode
self.openai = OpenAI()
self.sam3 = SAM3Predictor.from_pretrained("facebook/sam3.1")
self.qwen3vl = self._load_qwen3vl()
self.siglip = self._load_siglip2()
self.config = config or {}
def generate(self, spec):
if self.mode == "quick":
return self._quick_pipeline(spec)
else:
return self._strict_pipeline(spec)
# ============== 快速模式 ==============
def _quick_pipeline(self, spec):
prompt = self._build_prompt(spec)
# Stage 3: 純文生圖
resp = self.openai.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="high",
n=3,
)
candidates = [self._download(r.url) for r in resp.data]
for img in candidates:
# Stage 4: SAM 3.1 後驗抽 (class, bbox, mask)
sam_results = self.sam3.predict(
img,
concepts=[obj.class_name for obj in spec.objects],
)
# Stage 5: Qwen3-VL 抽屬性
for inst in sam_results:
inst.attrs = self.qwen3vl.extract_attrs(img, inst.bbox)
# Stage 6: 鬆過濾
if self._quick_filter(img, sam_results, spec):
yield self._build_output(img, sam_results, spec, mode="quick")
# ============== 嚴格模式 ==============
def _strict_pipeline(self, spec):
# Stage 2: 鎖三元組
locked = self._lock_triples(spec) # 每個 obj → (class, bbox, mask)
composite_mask = self._composite_masks(locked)
# Stage 3: GPT-Image-2 mask edit
prompt = self._build_prompt(spec)
resp = self.openai.images.edit(
image=self._blank_canvas(),
mask=composite_mask,
prompt=prompt,
size="1024x1024",
n=3,
)
candidates = [self._download(r.url) for r in resp.data]
for img in candidates:
# Stage 4: 驗證 & 細化
verify_masks = self.sam3.predict(
img,
concepts=[t.class_name for t in locked],
)
ious = [self._iou(v.mask, l.mask)
for v, l in zip(verify_masks, locked)]
if min(ious) < 0.7:
continue # reject
# Stage 5: 過濾
if self._strict_filter(img, verify_masks, locked, spec):
yield self._build_output(
img, verify_masks, spec,
mode="strict",
intent_ious=ious,
)
def _lock_triples(self, spec):
triples = []
for obj in spec.objects:
if obj.mask:
m = self._load_mask(obj.mask)
elif obj.ref_image:
m = self._sam3_from_ref(obj.ref_image, obj.bbox)
else:
m = self._bbox_to_blob(obj.bbox)
triples.append(LockedTriple(obj.class_name, obj.bbox, m))
return triples
def _build_output(self, img, masks, spec, mode, intent_ious=None):
return {
"image": img,
"masks": [m.mask for m in masks], # image-aligned
"annotation": {
"instances": [
{
"class_name": m.class_name,
"bbox": m.bbox, # SAM 抽的或 verify 的
"mask_pixel_grounding": True,
"spec_intent_iou": intent_ious[i] if intent_ious else None,
}
for i, m in enumerate(masks)
],
"scene": spec.scene.dict(),
"mode": mode,
},
}
參考資料
- SVGE 主文件 — 完整研究分析(4 篇分析 + 三子系統 + 風險 + 最小可行版本)
- SVGE 主文件 §8.A — A 子系統完整六階段管線
- OpenAI Images API — generate / edit / variations
- OpenAI Image generation guide — GPT Image 2 生成、編輯、mask 與輸出設定
- OpenAI ChatGPT Images help — Chrome / ChatGPT Images 生成與選區編輯說明
- COCO Panoptic API — panoptic ID map + segments_info 格式
- Cityscapes Dataset — semantic / instance 街景標註基準
- BDD100K paper — 多任務道路場景標註:檢測、lane、drivable area、天氣與時間標籤
- Mapillary Vistas paper — 高粒度街景語義與 instance 標註
- Crack500 repo — 純裂縫分割中 binary mask 的適用範圍
- RDD2022 paper — 道路病害類別與 bbox 標註範式
- SAM 3 GitHub
- Qwen3-VL GitHub
- SigLIP 2 HuggingFace
- FLUX.2 [klein] 9B(v1 升級目標)